
Tech Used
 Typescript: Programming Language used for the project.
Typescript: Programming Language used for the project. Next.js: Server side React framework.
Next.js: Server side React framework. Terraform: Infrastructure as code tool.
Terraform: Infrastructure as code tool. AWS: Cloud provider used with Terraform.
AWS: Cloud provider used with Terraform. Apache Kafka: Messaging System
Apache Kafka: Messaging System Redis: In memory database used for caching.
Redis: In memory database used for caching. MySQL: Server side react framework.
MySQL: Server side react framework.
Intro
The idea of Job Bored is an "Inbox Zero" for jobs. You get a feed of jobs from different public job sources according to your settings, and you can save them or hide them, until your inbox is zero.
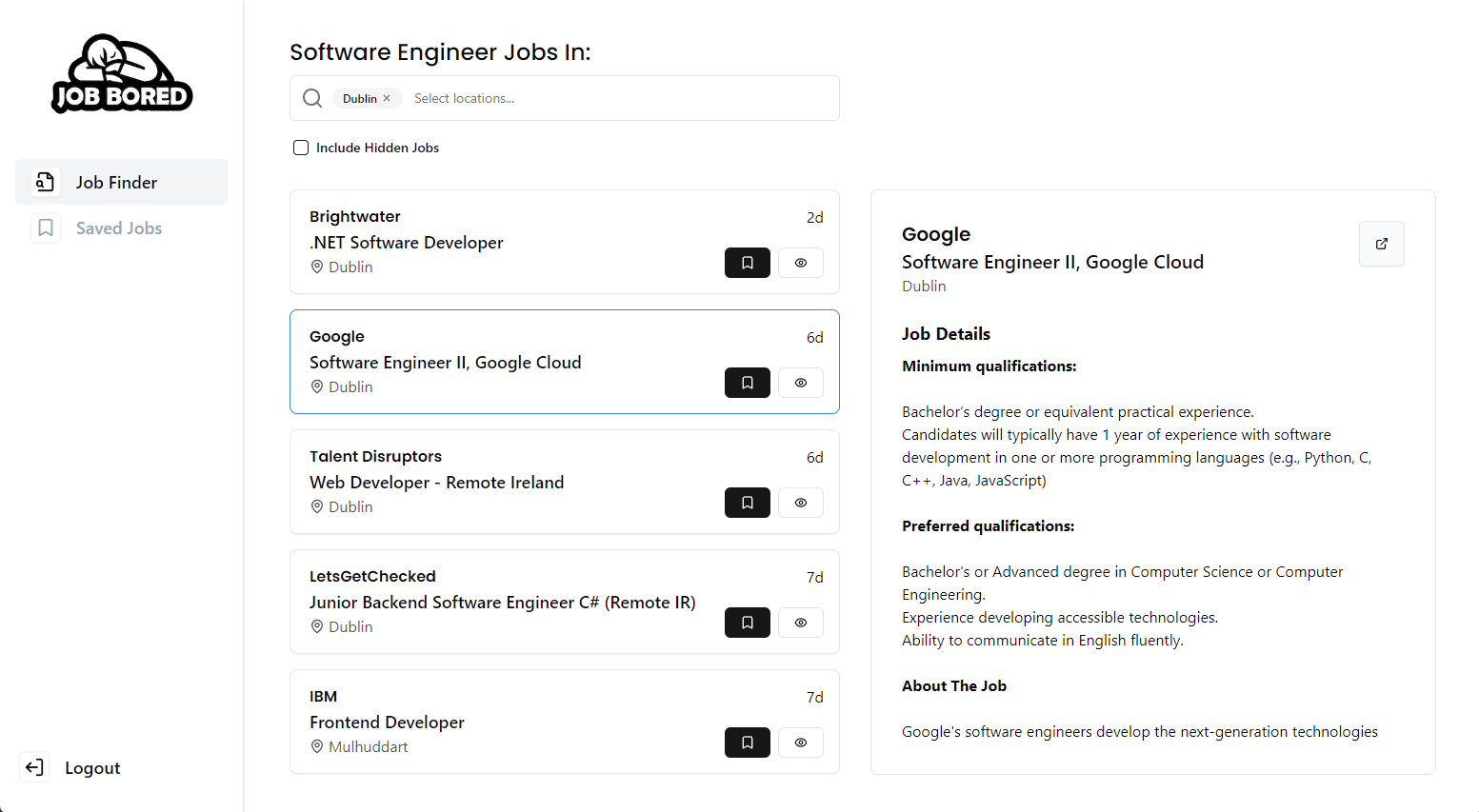
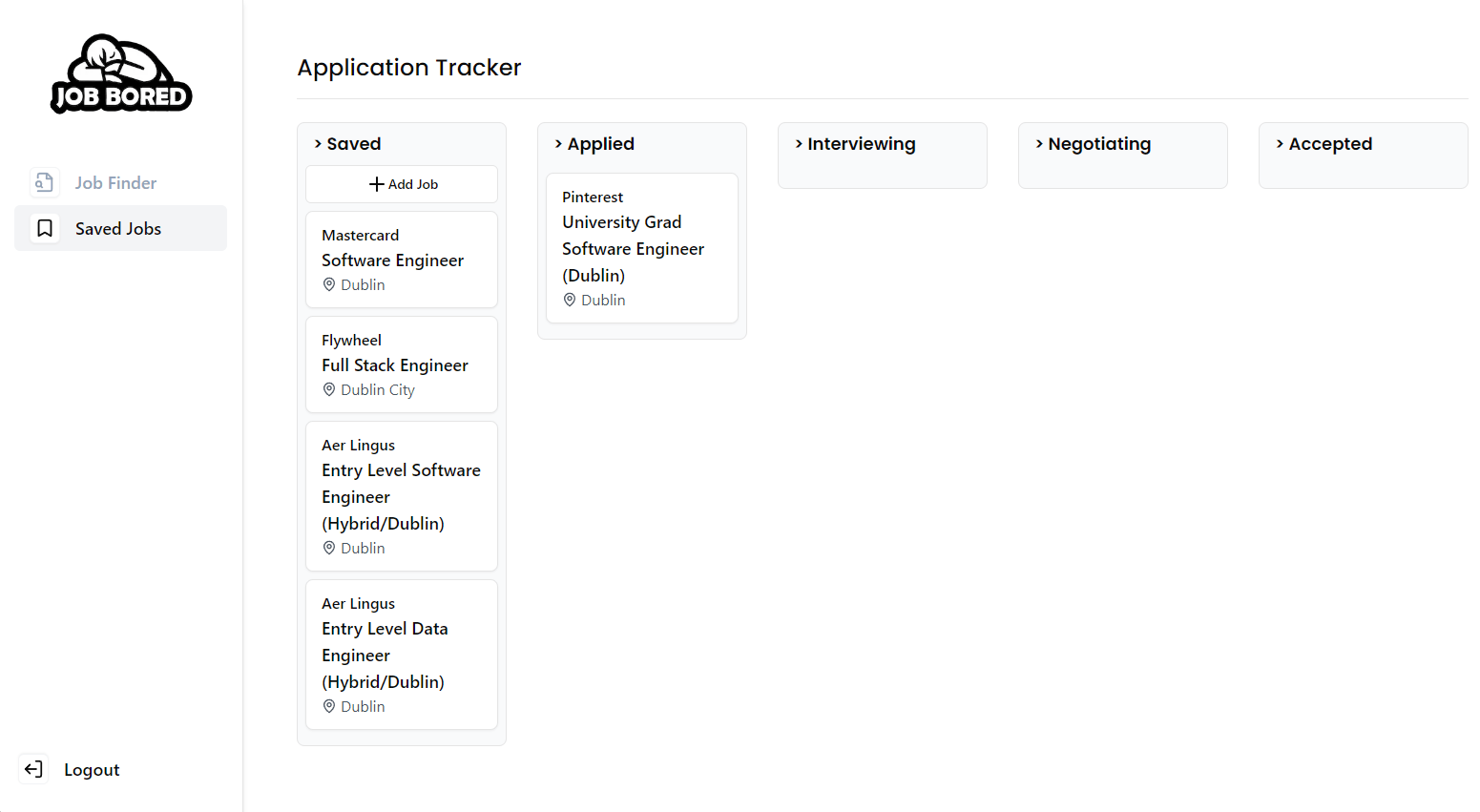
This later matured into an Application Tracker feature, which is a Kanban/Trello-like interface, to keep track of your applications throughout the process. It can sometimes be confusing to know if you applied to a certain job, and if they remove the listing you lose the job description. You can also add job posts from external services, and take notes on a job post. This provides a nice alternative to manually tracking jobs in a note-taking app.
Project Motivation
My current job search process is to search for "Software Engineer" jobs, sort by most recent, and manually guess if I have seen this job or not. With LinkedIn's repost and sponsored post feature, it can be confusing as to whether you've seen a job or not. Indeed is a better experience, and generally features the same jobs. Furthermore, you can miss jobs that are titled "Software Developer", and there are lots of job posts that say Senior position, even if you type entry-level.
While I'm pretty with my job hunting experience, I saw this as an opportunity to challenge myself to a fun project and try out new tools and technologies.
Some of these challenges included:
- Using the new Next.js 14 with React Server Components
- Scraping Public Job Data
- Utilising Kafka for Messaging and Decoupling
- Adding a Redis Cache Layer for quick reads.
- Provisioning Infrastructure with AWS and Terraform
Infrastructure
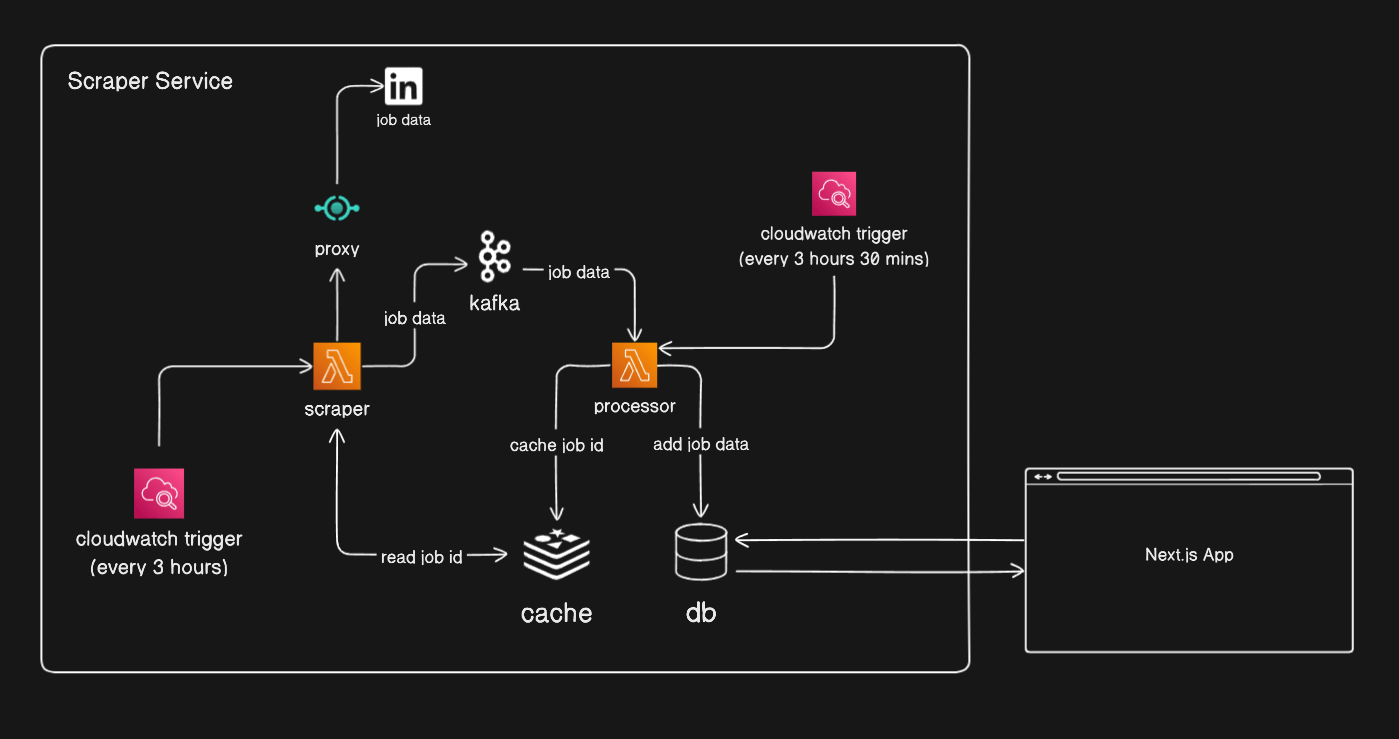
Overview
The app is created with a Typescript monorepo using TurboRepo. This allowed me to share the database code, packages and ORM amongst the web app and lambda functions with type-safe DB access 😁
The Web App is using Next.js with Prisma as the ORM, and a MySQL database hosted on the PlanetScale free tier.
The scraper service uses AWS Lambda, Cloudwatch provisioned with Terraform, and Redis and Kafka from Upstash.
Scraping Public Job Data
To get the job data, I had to leverage a scraper. I searched for public datasets, and/or APIs but the only solutions I could find were too expensive. I started with scraping public jobs from LinkedIn, meaning jobs that I could find while not signed in to LinkedIn.
I initially built the scraper in Golang using channels for concurrency and had a neat solution working pretty quickly. Spamming LinkedIn with requests would get my IP blocked pretty quickly. I leveraged a third-party proxy service, that provided residential proxies per GB of data proxied. This allowed me to scrape LinkedIn freely without getting blocked. To use the proxies, I was given a URL to the proxy pool and simply had to provide it when sending requests to LinkedIn.
However scraping LinkedIn you are limited to 1,000 jobs per search query, and none of the jobs are sorted. Not being able to sort jobs by most recent, makes it quite unusable for finding new jobs without creating a LinkedIn account, and trickier for scraping. For example, if you search for a job that has more than 1,000 results, you'll get 1,000 jobs in no particular order, missing out on the rest of the results.
I went with just scraping Software Engineer jobs in Dublin for the past week as there are less than 1,000 jobs, I can get them all and sort them. To get jobs for more locations I would have to manually configure search queries to provide the most coverage while being under the limit.
The scraper runs on an AWS Lambda that is triggered using Cloudwatch every x hours. The data is collected, parsed and sent to a Kafka topic. Any errors are sent to a separate error topic in Kafka.
Utilising Apache Kafka for Messaging and Decoupling
Apache Kafka is one of those tools I have heard about, but have never seen or used. The initial plan was to scrape data and send it straight into my database in the one lambda, but by sending it to a message queue I could decouple the scraper and the database, allowing me to update either part without affecting the other.
I was going to use AWS Simple Queue Service which would have been easier to set up and implement, but I decided to take the opportunity to use Kafka instead. I have all the buzzwords in my dictionary now, brokers, partitions, consumer groups, consumers and commits! It took a while to figure out, but it was really interesting to learn, it looks like a very powerful tool, and I'm excited to learn more about it. I used Kafka from Upstash as it is the cheapest option currently.
For processing the messages from Kafka, I used another lambda that would trigger shortly after the scraper. I looked into AWS Step functions, but it felt overkill for the scale of the current solution. This lambda would read messages with the job data from Kafka and add it to the database.
Adding a Redis Layer for Quick Reads
While scraping jobs, I used the jobId field from LinkedIn as a unique identifier. If I had already scraped the job I didn't want to process it again. Redis is an in-memory database, often used as a cache, for super-fast reads and writes. After processing the data, if it was successfully added to the database, then I would add its key to a set in Redis. While scraping for jobs I could check the cache for the jobId, and skip it if it already existed. The nature of LinkedIn scraping results in a lot of overlap when fetching jobs. Having Redis as a cache layer results in a quick and inexpensive way of checking the database.
Next Js 14
For the web app, I used Next JS 14 with React Server Components and Server Actions.
Server Components allows you to write server code directly in React components!
export default async function Page() {
// Server Code!
const jobs = await db.jobPost.findMany(...);
return (
<>
<div>
<JobPosts data={jobs} />
</div>
</>
);
}
The alternative without server components, would be to set up an API endpoint and have the client call this endpoint when they mount this code in useEffect hook. This code can also be wrapped in Suspense so that the HTML will be sent first while the data fetch waits to load.
Next JS also introduces Server Actions, which allows you to write functions and call them from client components. On a lower level, Next.js sends a POST request to this action. This means the server code is just a function. For a full-stack application, it makes it easy to move fast with type-safe access to the server.
There is a lot more to Server Components and Server Actions, but essentially it's a new and fun way to write server code 😎
Terraform
For provisioning the AWS Lambdas I used Terraform, an infrastructure as code tool. The main benefit of using Terraform is we have a single source of truth, state and version history for our infrastructure. Using the AWS console we can easily get lost at what is what and how our infrastructure ties together. My biggest struggle with Terraform was naming things, there isn't type safety on names, and it can get confusing linking services together. I enjoyed learning IAM policies, the least privilege principle of giving only the necessary permission to perform the job is neat.
Future Work
The app serves mostly for my learning, some things I want to try are:
- Moving the Redis, and Kafka to Terraform
- Local dev environment using docker-compose and seeding the database.
- Implement testing to different areas, unit tests, e2e, integration etc.
- CI/CD pipeline for deploying changes.
- IAM policies for collaboration.
- More apps for job seekers.
- Improve UI/UX,
- Learn about clean code practices and patterns in React.
- Research and implement logging and alert solutions.
- Update the scraper to handle adding locations automatically.
If you have any ideas, feel free to message me on LinkedIn!